이번글에서는 MATCH-V5의 MATCH 데이터와 TIMELINE 데이터를 가져와 하나의 DataFrame으로 만들어 보도록 하겠습니다. matchId를 가져오는 방법에 대해서는 이전글을 참고 해주시길 바랍니다.
https://big-data97.tistory.com/79
[게임 데이터 분석 #2] LOL 랭크 데이터 불러오기
이번 글에서는 데이터를 활용하여 A/B 테스트를 수행하기 위한 데이터셋 로딩 과정을 소개하려 합니다. A/B 테스트의 핵심 주제는 특정 상황이 승리에 어떤 영향을 미치는지에 대한 분석 및 검증
big-data97.tistory.com
MATCH 데이터 가져오기

MATCH 정보를 가져오는 창을 클릭해 열어보면 아래와 같이 데이터에 대한 설명이 작성되어 있습니다.
매우 많은 정보를 가지고 있기때문에 각 필드에 있는 데이터에 대한 정보를 알수록 더 많은 분석을 할 수 있을것 같습니다.

MATCH 데이터 아래의 각필드에 포함된 데이터의 정보는 아래와 같습니다.
MATCH 필드별 데이터 정보
- "assists": 참가자가 얻은 어시스트 수
- "baronKills": 참가자가 바론을 처치한 횟수
- "bountyLevel": 참가자의 현상금 레벨
- "champExperience": 참가자의 챔피언이 얻은 경험치
- "champLevel": 참가자의 챔피언 레벨
- "championId": 참가자가 플레이한 챔피언의 ID
- "championName": 참가자가 플레이한 챔피언의 이름
- "championTransform": 참가자의 챔피언 변형 상태
- "consumablesPurchased": 참가자가 구매한 소모품의 수
- "damageDealtToBuildings": 참가자가 건물에 가한 피해량
- "damageDealtToObjectives": 참가자가 목표물에 가한 피해량
- "damageDealtToTurrets": 참가자가 포탑에 가한 피해량
- "damageSelfMitigated": 참가자가 감소시킨 피해량
- "deaths": 참가자의 데스 수
- "detectorWardsPlaced": 참가자가 설치한 감지 와드의 수
- "doubleKills": 참가자의 더블킬 횟수
- "dragonKills": 참가자가 드래곤을 처치한 횟수
- "firstBloodAssist": 참가자가 첫 어시스트를 한 경우 true입니다.
- "firstBloodKill": 참가자가 첫 킬을 한 경우 true입니다.
- "firstTowerAssist": 참가자가 첫 포탑 어시스트를 한 경우 true입니다.
- "firstTowerKill": 참가자가 첫 포탑을 파괴한 경우 true입니다.
- "gameEndedInEarlySurrender": 게임이 조기 항복으로 끝난 경우 true입니다.
- "gameEndedInSurrender": 게임이 항복으로 끝난 경우 true입니다.
- "goldEarned": 참가자가 얻은 골드
- "goldSpent": 참가자가 사용한 골드
- "individualPosition": 참가자의 개인 포지션
- "inhibitorKills": 참가자가 억제기를 파괴한 횟수
- "inhibitorTakedowns": 참가자의 억제기 처치 횟수
- "inhibitorsLost": 참가자의 팀이 잃은 억제기의 수
- "item0" ~ "item6": 참가자가 게임 도중 사용한 각각의 아이템의 ID
- "itemsPurchased": 참가자가 구매한 아이템의 수
- "killingSprees": 참가자의 킬링 스프리 횟수
- "kills": 참가자의 킬 수
- "lane": 참가자의 라인
- "largestCriticalStrike": 참가자의 가장 큰 치명타 피해
- "largestKillingSpree": 참가자의 가장 큰 킬링 스프리
- "largestMultiKill": 참가자의 가장 큰 멀티 킬
- "longestTimeSpentLiving": 참가자가 한 번에 가장 오래 생존한 시간
- "magicDamageDealt": 참가자가 가한 마법 피해량
- "magicDamageDealtToChampions": 참가자가 챔피언에게 가한 마법 피해량
- "magicDamageTaken": 참가자가 받은 마법 피해량
- "neutralMinionsKilled": 참가자가 중립 미니언을 처치한 횟수
- "nexusKills": 참가자가 넥서스를 파괴한 횟수
- "nexusLost": 참가자의 팀이 넥서스를 잃은 횟수
- "nexusTakedowns": 참가자의 넥서스 처치 횟수
- "objectivesStolen": 참가자가 도난한 목표물의 수
- "objectivesStolenAssists": 참가자가 도난한 목표물의 어시스트 수
- "participantId": 참가자의 ID
- "pentaKills": 참가자의 펜타킬 횟수
- "physicalDamageDealt": 참가자가 가한 물리 피해량
- "physicalDamageDealtToChampins": 참가자가 챔피언에게 가한 물리 피해량
- "physicalDamageTaken": 참가자가 받은 물리 피해량
- "profileIcon": 참가자의 프로필 아이콘
- "puuid": 참가자의 PUUID
- "quadraKills": 참가자의 쿼드라킬 횟수
- "riotIdName": 참가자의 Riot ID 이름
- "riotIdTagline": 참가자의 Riot ID 태그라인
- "role": 참가자의 역할
- "sightWardsBoughtInGame": 참가자가 게임 도중 구매한 시야와드의 수
- "spell1Casts", "spell2Casts", "spell3Casts", "spell4Casts": 참가자의 각 스킬 사용 횟수
- "summoner1Casts", "summoner2Casts": 참가자의 각 소환사 스킬 사용 횟수
- "summoner1Id", "summoner2Id": 참가자의 각 소환사 스킬 ID
- "summonerId": 참가자의 소환사 ID
- "summonerLevel": 참가자의 소환사 레벨
- "summonerName": 참가자의 소환사 이름
- "teamEarlySurrendered": 참가자의 팀이 조기 항복한 경우 true입니다.
- "teamId": 참가자의 팀 ID
- "teamPosition": 참가자의 팀 내에서의 포지션
- "timePlayed": 참가자가 게임에 참여한 시간
- "totalDamageDealt": 참가자가 가한 총 피해량
- "totalDamageDealtToChampions": 참가자가 챔피언에게 가한 총 피해량
- "totalDamageShieldedOnTeammates": 참가자가 팀원에게 적용한 총 피해 방어막
- "totalDamageTaken": 참가자가 받은 총 피해량
- "totalHeal": 참가자가 받은 총 회복량
- "totalHealsOnTeammates": 참가자가 팀원에게 적용한 총 회복량
- "totalMinionsKilled": 참가자가 처치한 미니언의 수
- "totalTimeCCDealt": 참가자가 적에게 가한 총 CC(군중 제어) 시간
- "totalTimeSpentDead": 참가자가 총 사망한 시간
- "totalUnitsHealed": 참가자가 치료한 유닛의 총 수
- "tripleKills": 참가자의 트리플킬 횟수
- "trueDamageDealt": 참가자가 가한 진실 피해량
- "trueDamageDealtToChampions": 참가자가 챔피언에게 가한 진실 피해량
- "trueDamageTaken": 참가자가 받은 진실 피해량
- "turretKills": 참가자가 포탑을 파괴한 횟수
- "turretTakedowns": 참가자가 포탑을 파괴한 횟수
- "turretsLost": 참가자의 팀이 잃은 포탑의 수
- "unrealKills": 참가자의 언리얼 킬 횟수
- "visionScore": 참가자의 시야 점수
- "visionWardsBoughtInGame": 참가자가 게임 도중 구매한 비전 와드의 수
- "wardsKilled": 참가자가 파괴한 와드의 수
- "wardsPlaced": 참가자가 설치한 와드의 수
- "win": 참가자의 승리 여부
TIMELINE 데이터 가져오기


TIMELINE 데이터는 반환되는 값에 대한 명확한 설명이 제공되지 않습니다. 그러나, 각 열의 이름을 통해 데이터의 내용을 추측해볼 수 있습니다.
먼저, TIMELINE 데이터의 구조를 살펴봅시다.
하나의 경기에 대한 데이터는 상당히 방대하므로, JSON Viewer를 사용하여 데이터를 깔끔하게 정렬하고 쉽게 살펴볼 수 있습니다.
사용한 JSON Viewer 웹사이트의 링크는 아래에 첨부해두겠습니다.

우선 크게는 metadata필드와 info필드로 구성되어 있습니다.

metadata 필드에는 matchid와 참가자 10명의 puuid가 있습니다. 해당 정보는 info필드의 participants와 같습니다.

info 필드에는 frames필드와 metadata 필드에도 포함된 participants의 puuid가 담겨있는 participants필드가있습니다.

info 필드 내부의 frames 필드에는 시간별로 발생한 events와 소환사의 챔피언의 현재 상황을 나타내는 participantFrames 필드가 포함되어 있습니다. 특히, events 필드에는 다음과 같은 데이터가 포함되어 있습니다.
- type: 이벤트 타입
- timestamp: 이벤트가 발생한 시간
- position: 이벤트가 발생한 위치
- killerId: 킬을 한 챔피언의 ID
- victimId: 킬당한 챔피언의 ID
- assistingParticipantIds: 어시스트한 참가자들의 ID 리스트
type에는 다음 값들이 있습니다.
- CHAMPION_KILL: 한 챔피언이 다른 챔피언을 처치한 경우입니다. 이 이벤트에는 킬한 챔피언, 킬당한 챔피언, 어시스트한 챔피언 등의 정보가 포함됩니다.
- WARD_PLACED: 와드를 설치한 경우를 나타냅니다. 이 이벤트에는 와드를 설치한 참가자, 와드의 종류 등의 정보가 포함됩니다.
- WARD_KILL: 와드를 파괴한 경우를 나타냅니다. 이 이벤트에는 와드를 파괴한 참가자, 파괴된 와드의 종류 등의 정보가 포함됩니다.
- BUILDING_KILL: 건물 (터렛, 억제기, 넥서스)을 파괴한 경우입니다. 이 이벤트에는 건물을 파괴한 팀, 건물의 종류 및 위치 등의 정보가 포함됩니다.
- ELITE_MONSTER_KILL: 엘리트 몬스터 (용, 바론, 전령)를 처치한 경우입니다. 이 이벤트에는 몬스터를 처치한 팀, 몬스터의 종류 등의 정보가 포함됩니다.
- ITEM_PURCHASED: 아이템을 구매한 경우입니다. 이 이벤트에는 아이템을 구매한 참가자, 구매한 아이템의 정보 등이 포함됩니다.
- ITEM_SOLD: 아이템을 판매한 경우입니다. 이 이벤트에는 아이템을 판매한 참가자, 판매한 아이템의 정보 등이 포함됩니다.
- ITEM_DESTROYED: 아이템이 파괴된 경우입니다. 이 이벤트에는 아이템을 소유하고 있던 참가자, 파괴된 아이템의 정보 등이 포함됩니다.
- ITEM_UNDO: 아이템 구매를 취소한 경우입니다. 이 이벤트에는 아이템 구매를 취소한 참가자, 취소한 아이템의 정보 등이 포함됩니다.
- SKILL_LEVEL_UP: 스킬 레벨을 올린 경우입니다. 이 이벤트에는 스킬 레벨을 올린 참가자, 레벨을 올린 스킬의 정보 등이 포함됩니다.
파이썬 구현
MATCH와 TIMELINE 데이터를 얻기 위해선 이전에 설명한 과정을 반복해야 하며, 여러 경기의 데이터를 한 번에 가져오기 위한 반복문이 필요합니다. 따라서 이제부터는 Class를 생성하여 데이터를 추출하는 과정을 진행하겠습니다.
import requests
import pandas as pd
class RiotAPI:
BASE_URL = "https://kr.api.riotgames.com/lol"
# RiotAPI class가 실행되면 api_key,region,teir,rank를 인자로 받음
def __init__(self, api_key,region,teir,rank):
self.api_key = api_key
self.region = region
self.teir = teir
self.rank = rank
# API데이터를 불러오는 코드, _로 숨김처리가 된 상태
def _get(self, url):
response = requests.get(url)
response.raise_for_status()
# 호출된 API를 반환
return response.json()
# class인자로 입력한 티어,랭크 데이터를 통해 해당 티어의 user 정보를 반환
def get_league_entries(self, page_number=1, queue='RANKED_FLEX_SR'):
url = f"{self.BASE_URL}/league/v4/entries/{queue}/{self.teir}/{self.rank}?page={page_number}&api_key={self.api_key}"
# get함수를 통해 호출된 API 반환
return pd.DataFrame(self._get(url))
# get_league_entries 함수를 실행시켜 얻은 summonerName을 저장
# 각 summonerName의 값을 get_summoner_info 함수에 인자로 넘김
# get_summoner_info 함수가 실행되고 반환 되는 값(puuid) n_summoners(4)개를 리스트로 반환
def build_puuid_list(self, n_summoners=4):
league_df = self.get_league_entries()
# n_summoners 변수에 대입된 수만큼의 summonerName을 가져옴
summoner_names = league_df['summonerName'].head(n_summoners)
return [self.get_summoner_info(name) for name in summoner_names]
# build_puuid_list 함수에서 받은 인자를 통해 puuid를 반환
def get_summoner_info(self, summoner_name):
url = f"{self.BASE_URL}/summoner/v4/summoners/by-name/{summoner_name}?api_key={self.api_key}"
return self._get(url)['puuid']
# build_puuid_list 함수에서 반환된 puuid를 통해 matchid를 구하는 함수
def get_match_ids(self, start=0, count=20):
match_ids = []
for puuid in self.build_puuid_list():
url = f"https://{self.region}.api.riotgames.com/lol/match/v5/matches/by-puuid/{puuid}/ids?start={start}&count={count}&api_key={self.api_key}"
# puuid하나당 20판씩 나오기 때문에 puuid하나당 10개씩 추출
match_ids.extend(self._get(url)[:10])
return match_ids
# get_match_ids 함수에서 반환된 matchid들을 사용해 경기내용을 가져오는 함수
def get_classic_match_ids(self):
classic_match_ids = []
for match_id in self.get_match_ids():
url = f"https://{self.region}.api.riotgames.com/lol/match/v5/matches/{match_id}?api_key={self.api_key}"
match_data = self._get(url)
# gameMode가 "CLASSIC"이면 소환사 협곡을 나타냄
# 소환사 협곡 데이터만 추출
if match_data['info']['gameMode'] == "CLASSIC":
classic_match_ids.append(match_data['metadata']['matchId'])
# 경기 내용 반환
return classic_match_ids
# get_classic_match_ids 함수에서 반환된 경기내용중 timeline 데이터와 함칠 key값을 포함한
# 경기내용을 DataFrame으로 가져오는 함수
def get_match_data(self):
# DataFrame으로 만들기 위해 생성된 리스트
key_list = []
participants_data_list = []
challenges = []
for match_id in self.get_classic_match_ids():
url = f"https://{self.region}.api.riotgames.com/lol/match/v5/matches/{match_id}?api_key={self.api_key}"
match_data = self._get(url)
# timeline 데이터와 합치기위해 key 값을 만들어 준다. 이때 key 값은 puuid + matchid로 설정한다.
for value in range(len(match_data['info']['participants'])):
key_list.append({'key':match_data['info']['participants'][value]['puuid'] + match_data['metadata']['matchId']})
for participant in match_data['info']['participants']:
# participant 필드의 데이터를 participants_data_list 리스트에 넣음
participants_data_list.append(participant)
# challenges 열은 딕셔너리 형태로 되어 있기 때문에 풀어서 열에 붙이기 위해 리스트에 넣음
challenges.append(participant['challenges'])
# key로 잡을 열과 participant 필드의 데이터들을 합치고 DataFrame로 생성, challenges 열은 풀어서 붙일 예정이기 때문에 삭제
key_participants_data_df = pd.concat([pd.DataFrame(key_list),pd.DataFrame(participants_data_list)],axis=1).drop(columns=['challenges'])
# challenges열을 풀어서 데이터 프레임으로 따로 생성
challenges_df = pd.DataFrame(challenges)
# 만들어진 두개의 DataFrame을 하나로 합친후 return
match_df = pd.concat([key_participants_data_df, challenges_df], axis=1)
return match_df
# timeline 데이터안의 필드를 DataFrame으로 만드는 함수
def get_timeline_data(self):
# DataFrame으로 만들기 위해 생성된 list
timeline_list = []
puuid_list = []
# timeline 데이터를 matchId수 만큼 불러와 원하는 시간까지의 발생한 이벤트를 가져온다
for matchid in self.get_classic_match_ids():
url = f'https://asia.api.riotgames.com/lol/match/v5/matches/{matchid}/timeline?api_key={self.api_key}'
data = self._get(url)
for frame_cnt in range(len(data['info']['frames'])):
# 40분까지의 게임내의 이벤트를 가져오는 코드(현재는 모든 시간에 해당하는 데이터를 가져온다)
# if data['info']['frames'][i]['timestamp'] / 1000 /60 <=40:
for event_cnt in range(len(data['info']['frames'][frame_cnt]['events'])):
# 발생한 events의 type이 CHAMPION_KILL인 경우 해당 events의 정보를 timeline_list에 넣는다
if data['info']['frames'][frame_cnt]['events'][event_cnt]['type'] == 'CHAMPION_KILL':
timeline_list.append(data['info']['frames'][frame_cnt]['events'][event_cnt])
# CHAMPION_KILL events가 발생한 경우 죽인사람의 ID와 참가자의 아이디를 매핑해 해당 참가자의 puuid를 가져온다(key값을 만들기 위해)
# value 변수에 죽인 사람의 ID 번호를 대입
value = data['info']['frames'][frame_cnt]['events'][event_cnt]['killerId']
# killerId는 1~10의 값을 가지고 participants 필드는 list로 되어있어 0부터 카운트 하기 때문에 -1을 해준다
# 구해진 puuid와 matchid를 결합해 key값을 만든다.
puuid_list.append({'key':data['info']['participants'][value-1]['puuid'] + data['metadata']['matchId']})
timeline_df = pd.concat([pd.DataFrame(timeline_list),pd.DataFrame(puuid_list)],axis =1)
return timeline_df
# class에서 초기에 실해되는 인자를 넣어준다
api = RiotAPI('your_api_key','asia','GOLD','III')코드 설명
1. RiotAPI 라는 이름의 class를 선언합니다.

2. __init__ 함수는 class가 실행되면 가장 먼저 실행되는 함수입니다.
3. _get 함수는 api를 요청한뒤 json형태의 데이터를 반환 해주는 함수입니다.
해당 함수는 _로 인해 숨김처리가 된 상태입니다.

4. get_legue_entries 함수는 설정한 랭크와 티어에 해당하는 솔로랭크에 속한 소환사를 정보를 DataFrame로 반환하는 함수입니다. 반환된 DataFrame은 아래와 같습니다.
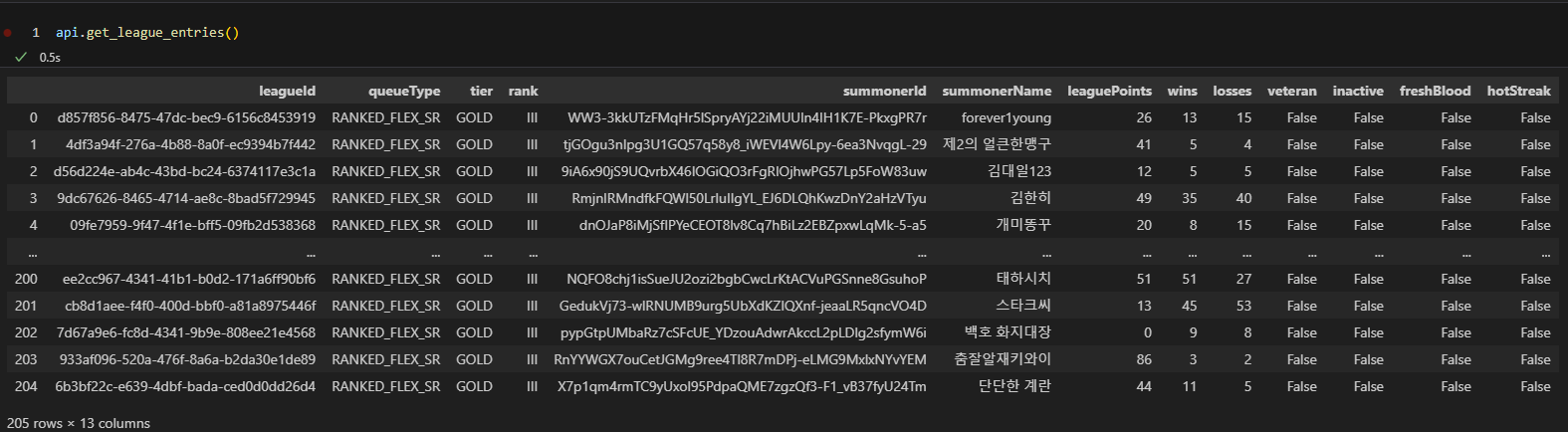

위 부분은 조금 헷갈리기 쉬운 부분입니다.
5. build_puuid_list 함수가 호출되면, 먼저 get_league_entries 함수가 실행되어 지정된 티어와 랭크에 속한 사용자들의 정보를 DataFrame 형태로 가져옵니다.
이 DataFrame에서 'summonerName' 컬럼의 값들을 n_summoners(함수 호출 시 설정 가능한 매개변수)의 수만큼 추출합니다.
그 후, 각각의 소환사 이름을 get_summoner_info 함수에 인자로 전달하여 해당 소환사의 고유 식별자인 'puuid'를 추출합니다. 이렇게 얻어진 'puuid'들은 하나의 리스트로 구성되어 반환됩니다.
6. get_summoner_info 함수는 build_puuid_list 함수 내에서 호출되며, 인자로 전달받은 소환사 이름(summonerName)을 통해 해당 소환사의 고유 식별자인 'puuid'를 반환합니다.
7. build_puuid_list 함수는 get_summoner_info 함수를 통해 얻은 각 'puuid'를 리스트로 취합하여 반환합니다.
이때, 반환된 리스트의 길이는 n_summoners의 값에 해당하며, 예를 들어 n_summoners가 4라면 4개의 'puuid'가 담긴 리스트가 반환됩니다. 이는 4명의 소환사 각각에 대한 'puuid'를 추출한다는 것을 의미합니다. 추출한 puuid 리스트는 아래와 같습니다.


8. get_match_ids 함수는 build_puuid_list 함수로부터 반환받은 'puuid' 리스트를 사용하여 각 소환사의 매치 ID 정보를 가져옵니다. 이 때 각 소환사 별로 10개의 매치 ID가 추출되며, 이는 각각 별도의 리스트로 구성됩니다. 따라서, 'puuid' 리스트에 4개의 'puuid'가 있다면, 총 4개의 리스트(각 리스트는 10개의 매치 ID를 포함)가 생성됩니다.
이렇게 생성된 여러 리스트를 하나의 리스트로 합치기 위해 extend 함수를 사용합니다. 이 함수는 리스트에 다른 리스트의 모든 요소를 추가하는 역할을 합니다. 따라서, 'puuid'가 4개일 경우 총 40개의 매치 ID가 하나의 리스트에 담기게 됩니다.
따라서 get_match_ids 함수는 40개의 매치 ID가 담긴 하나의 리스트를 반환합니다.

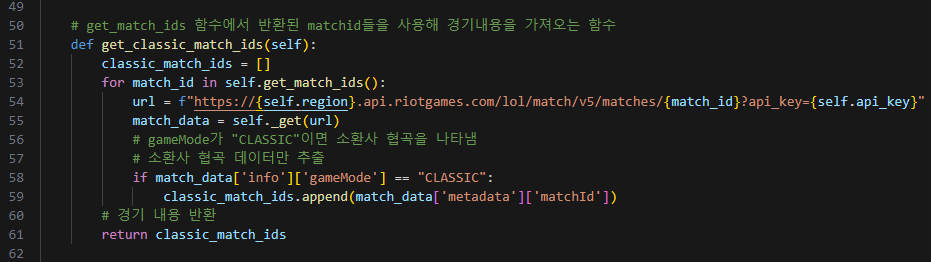
9. get_classic_match_ids 함수는 get_match_ids 함수를 통해 얻은 매치 ID 리스트를 활용하여 각 매치의 세부 정보를 API를 통해 요청합니다. 각 매치의 정보 중 'gamemode' 항목이 'CLASSIC'인 경우, 해당 매치의 ID를 classic_match_ids 리스트에 추가합니다. 이는 일종의 필터링 과정으로 이해하시면 됩니다.
'CLASSIC' 모드는 '소환사의 협곡' 게임 모드를 가리키며, 이 게임 모드에는 '솔로 랭크', '자유 랭크', '일반' 등의 게임 유형이 포함됩니다. 따라서, get_classic_match_ids 함수의 최종 결과는 '소환사의 협곡' 게임 모드에서 진행된 매치들의 ID 리스트입니다.
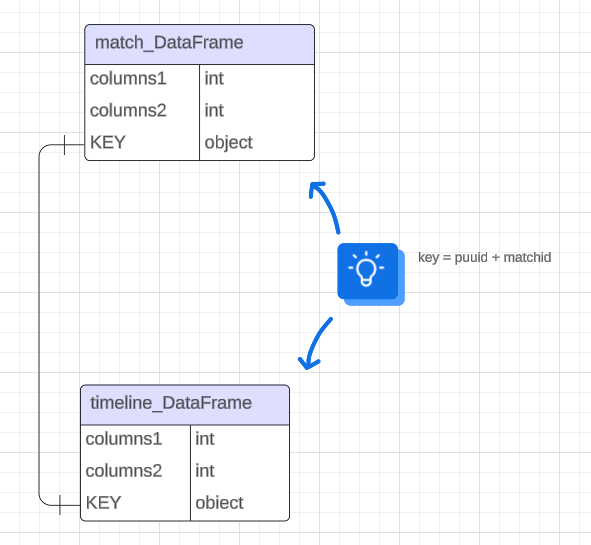
10. 위의 그림처럼 match 데이터와 timeline 데이터를 key를 기준으로 하나로 합칠것입니다.
key는 소환사의 고유 puuid와 한경기에 해당하는 고유한 matchid를 합친 값으로 할것입니다. 이 방식을 사용하면, 같은 소환사가 여러 게임에서 나타나더라도 각 게임의 'matchid'가 다르므로 키 값은 고유하게 유지됩니다. 따라서, 이 키를 기준으로 매치 데이터와 타임라인 데이터를 합칠 수 있습니다. 이렇게 하면 각 소환사의 게임별 세부 정보를 효과적으로 관리하고 분석할 수 있습니다.

11. get_match_data 함수는 'MATCH-V5' API를 활용하여 매치 데이터를 가져오는 역할을 합니다. 이 함수는 get_classic_match_ids 함수를 통해 필터링된 매치 ID를 활용하여 API를 호출합니다.
이 함수는 DataFrame을 생성하는 과정에서 'timeline' DataFrame과 결합하기 위해, 소환사의 'puuid'와 'matchid'를 결합한 값을 기준키로 설정합니다.
그 다음, 매치 데이터의 'info' 필드 안에 있는 'participants' 필드의 값들을 빈 리스트에 추가합니다. 이 과정에서 'participants' 필드 내부에 있는 'challenges' 필드는 딕셔너리 형태로 되어 있으므로, DataFrame으로 변환하면 'challenges' 열 내의 값들이 딕셔너리 형태로 표현됩니다.
그렇기 때문에 'challenges' 필드 값들을 개별 열로 변환하여 DataFrame에 합쳐줍니다.
이 과정을 통해 총 3개의 DataFrame이 생성되며, 이들을 하나로 연결합니다. 이 때 열 방향으로 데이터를 합쳐, 각 소환사와 해당 소환사의 'puuid'가 일치하도록 설정합니다.
이렇게 최종적으로 생성된 DataFrame의 형태는 아래와 같습니다.


12. get_timeline_data 함수는 'MATCH-V5' API를 활용하여 타임라인 데이터를 가져오는 역할을 합니다. 이 함수는 get_classic_match_ids 함수를 통해 필터링된 매치 ID를 활용하여 API를 호출합니다.
이 함수는 'info' 필드 내의 'frames' 필드를 주로 다룹니다. 'frames' 필드는 게임의 시간대별 정보를 담고 있으므로, 'frames' 필드의 각 요소에 대해 반복 처리를 합니다.
주석 처리된 한 줄의 코드는 특정 시간대의 게임 데이터를 추출하는 코드입니다. 이 코드의 시간을 2분 전의 데이터만을 대상으로 한다면, 게임 초반의 상황(예: 인베이드)에 대한 정보를 얻는 데 활용할 수 있습니다.
'events' 필드 내의 'type'이 'CHAMPION_KILL'인 데이터만을 추출하여 'Timeline_list'에 추가합니다. 이는 챔피언이 죽은 사건에 대한 정보만을 추출하는 것을 의미합니다.
이 때, 죽인 챔피언의 'puuid'를 얻기 위해 'killerId'를 'value' 변수에 대입합니다. 이 'value'를 통해 'info' 필드 내의 'participants' 필드의 'puuid' 값을 매핑하여 가져옵니다. 이후, 이 값과 해당 게임의 'matchid'를 결합하여 key를 생성합니다.
이렇게 생성된 key를 이용하여, 'CHAMPION_KILL' 이벤트에 대한 정보를 담은 DataFrame과 기존의 DataFrame을 결합합니다.
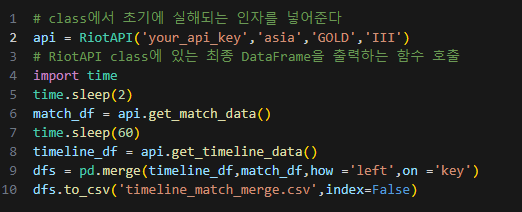
13. 마지막 과정에서는 앞서 생성한 두 개의 DataFrame을 하나로 병합(Merge)합니다.
1분 동안 대기하는 이유는 API 호출에 대한 제한 때문입니다. API 키당 1분에 20회의 호출이 가능하므로, 이 제한을 넘지 않기 위해 1분 동안 프로그램을 일시 중지합니다. 이렇게 하면 API 호출에 대한 제한을 준수하면서도 오류 없이 프로그램을 실행할 수 있습니다.
이슈
- API 요청에 실패한 경우를 처리하는 예외 처리 코드 추가
- API 요청에 제한이 있을 수 있으므로, 요청이 실패하거나 제한에 도달했을 때 재시도하는 로직 추가
- get_classic_match_ids 메서드에서는 모든 매치 데이터를 가져온 후에 "CLASSIC" 모드인지 확인하기 때문에 불필요한 데이터 전송을 초래할 수 있음, 가능하다면 "CLASSIC" 모드의 매치만 요청하는 로직 추가(이전 글의 이슈와 동일)
- API 요청후 DataFrame을 만드는 속도가 매우 느림
json viewer 사이트
Online JSON Viewer and Formatter
jsonviewer.stack.hu
'게임 데이터 분석' 카테고리의 다른 글
| [게임 데이터 분석 #2] LOL 랭크 데이터 불러오기 (0) | 2023.12.06 |
|---|---|
| [게임 데이터 분석 #1] LOL API 발급 및 데이터 불러오기 (0) | 2023.12.03 |
| [게임 데이터 분석 #8] opencv를 활용해 비행기 이동 경로, 낙하 경로 등 출력하기 (0) | 2023.07.06 |
| [게임 데이터 분석 #7] DB데이터 사용 및 지도에 자지장 그리기 (1) | 2023.07.02 |
| [게임 데이터 분석 #6] Mysql 설치, 연동 및 DB에서 데이터 가져오기 (0) | 2023.07.01 |



